


Qualche giorno fa abbiamo anticipato sul nostro blog il prossimo avvento di un nuovo modello di intelligenza artificiale chiamato KELM, sviluppato da Google, che promette di ristrutturare completamente il suo sistema di machine learning eliminando le tossine messe in circolo dalla cattiva informazione. Approfondiamo dunque in questo articolo i dettagli tecnici di KELM e le sue implicazioni per il ranking.
Addestramento per intelligenze artificiali: cosa cambia con KELM
Punto di partenza per intuire la straordinarietà di Google KELM è comprendere il funzionamento dei modelli impiegati sinora dal team di Mountain View per addestrare l’intelligenza artificiale del motore di ricerca a interpretare il linguaggio naturale. I modelli NLP come BERT, attuale punto di riferimento del settore, vengono infatti addestrati sulla base del linguaggio naturale contenuto nei materiali “autentici” presenti sul web e poi messi a punto tramite task specificamente designati per loro. I problemi di un addestramento di questo genere sono principalmente due:
- La limitatezza del corpus di conoscenza rappresentato dai testi utilizzati;
- Il modo in cui quei testi sono scritti, poiché spesso gli elementi fattuali sono sepolti all’interno di periodi prolissi, complessi, se non volutamente oscuri e faziosi.
Questa “tossicità” – così viene definita dal team AI di Google – contribuisce a influenzare il modello NLP risultante, pregiudicandone l’imparzialità. La novità introdotta da Google KELM risiede proprio nella diversa sorgente del materiale impiegato per nutrire il machine learning, costituita infatti dai Knowledge Graph (KG). Essendo composti di dati strutturati estratti da fonti affidabili – ad esempio Wikipedia – e sottoposti a ulteriori controlli sia automatizzati sia manuali, questi ultimi svolti da veri esseri umani che si assicurano che ogni contenuto inappropriato o incorretto venga rimosso, i KG rappresentano un corpus di informazioni fattuali per natura. Un modello basato su di essi assicura di conseguenza un’accuratezza maggiore e una tossicità inferiore. La loro natura così particolare rende però particolarmente difficile integrarli nel framework già esistente.
Come funziona (in soldoni) Google KELM
In uno studio presentato all’edizione 2021 del NAAL (North American Chapter of the Association for Computational Linguistics), il team AI di Google ha spiegato il modo in cui, utilizzando i KG pubblicamente disponibili sulla versione inglese di Wikidata, KELM converte questi dati in testi scritti in un linguaggio naturale, utilizzati successivamente per l’autoapprendimento della macchina.
L’informazione contenuta nei KG è generalmente rappresentata in triple costituite da un soggetto, un predicato e un oggetto messi in relazione fra loro. Questi gruppi di dati sintetici (entity subgraph) vengono convertiti in linguaggio naturale attraverso un procedimento già utilizzato dai modelli NLP e chiamato data-to-text generation; convertire un KG intero in testo naturale pone tuttavia delle difficoltà aggiuntive, poiché porta con sé una trama di entità e relazioni estremamente più vasta e diversificata rispetto ai dataset più limitati che vengono di norma utilizzati come riferimento.
Questa trama deve dunque essere segmentata in entity subgraph comprensibili e utilizzabili per la creazione di frasi fluide, naturali e dotate di significato, un processo che può essere rappresentato graficamente come segue:
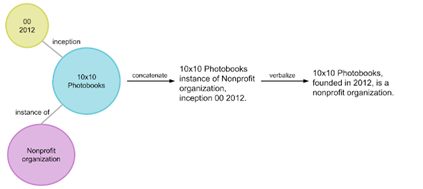
Fonte immagine: https://ai.googleblog.com/2021/05/kelm-integrating-knowledge-graphs-with.html
È qui che entra in azione il TEKGEN (Text from KG Generator), composto da:
- Un grande corpus di testi, estratti da Wikipedia, allineati euristicamente con le triple dei KG di Wikidata;
- Un generatore di testo in grado di convertire le triple dei KG in testo;
- Un creatore di entity subgraph che generi gruppi di triple da verbalizzare insieme;
- Un filtro da utilizzare nella fase finale per rimuovere i prodotti di bassa qualità. Questo componente è altrettanto cruciale degli altri, se consideriamo che nei modelli di machine learning ogni output si ritrasforma ciclicamente in input e un errore in tale fase pregiudicherebbe la bontà dell’intero esperimento.
Il risultato di questa catena di montaggio è il corpus di KELM, acronimo di Knowledge-Enhanced Language Model, che abbraccia circa 18 milioni di frasi distribuite su 45 milioni di triple e 1500 predicati.
L’impatto sul ranking e le relazioni di KELM con MUM
Come anticipato nel nostro Digest di giugno, il modello nasce dall’esigenza di ridurre la faziosità del modello di analisi del linguaggio naturale. Considerato che al momento attuale Google non effettua il fact checking dei contenuti che mostra in SERP, non è possibile prevedere quale potrebbe essere l’impatto di KELM sul ranking dei siti web, ma possiamo ragionevolmente immaginare che avrà un impatto negativo sul posizionamento dei siti che in genere promuovono idee non corroborate da fatti. Considerato lo sforzo compiuto da Mountain View nell’ultimo anno per arginare il proliferare di contenuti allarmisti e complottisti, è altrettanto ragionevole prevedere che, una volta introdotto KELM, gli scricchiolii si sentiranno soprattutto fra i siti di ambito medico e, come sempre, tutti quelli di tipo YMYL.
La portata di KELM però potrebbe estendersi oltre i confini di Google, poiché il corpus su cui si basa il nuovo modello è stato rilasciato sotto una licenza Creative Commons e ciò significa che, almeno in teoria, altre aziende potrebbero adottarlo, applicandolo non solo ai classici motori di ricerca orizzontali, ma anche a ciò che non siamo abituati a considerare motore di ricerca e che in realtà lo sono a pieno titolo: le piattaforme social.
Da Mountain View si fa inoltre intendere una certa connessione fra Google KELM e Google MUM, la tecnologia di intelligenza artificiale in fase di sperimentazione che dovrebbe permettere al motore di condensare, in un unico risultato, risposte a domande complesse che attualmente richiedono molte fasi distinte di ricerca. Il nuovo algoritmo infatti non verrà rilasciato finché il team di Google non si sarà accertato che MUM sia effettivamente in grado di fornire risposte imparziali. L’approccio sviluppato con KELM sembra andare esattamente nella stessa direzione delineata per MUM.
Google KELM: a quando l’uscita?
Nella fase di sviluppo in cui ci troviamo attualmente, l’arrivo di KELM è ancora lontano all’orizzonte. Dopo il vaglio della comunità scientifica e le prove in ambiente controllato, seguirà sicuramente una lunga fase di sperimentazione guidata, come sempre, dalla ricerca statunitense. Per ora, quindi, limitiamoci a sognare il mondo virtuale che verrà, dominato da un’informazione degna di questo nome, dove fatti e opinioni, od opinioni e allucinazioni, non vengano più confusi.
