


Google announced an update on its algorithm on October 25th, 2019: starting from this date, for the English market queries (and from the 9th of December for the queries in other 70 languages), Google has started to interpret the research of the users by integrating BERT, the NLP model (Natural Language Processing) developed in 2018 by the researchers of the Google AI division, to improve the comprehension of the search intent of Google users. But what is the BERT and how it affects SEO activities?
What is an NLP model?
Let’s start step by step: the computational linguistics is the branch that aims to develop models that allow a machine to comprehend the natural language in a corpus of documents. The objective is to get close to a human being as much as possible, being able to comprehend a text and the relationship between an entity and a context. What seems to be natural, in fact, turns out to be a challenge for an algorithm and in the case of Google, a search engine.
A few steps back: in search of the user intent
Google has had its holy Grail for years when we refer to the comprehension of the user search intent, a necessary condition to ensure the best stage for its advertisements, and consequentially its profit. In this sense, over the years, we have seen efforts carried out by the engine, with different approaches, and in an increasingly accurate way:
- Refinements of research in an “active” way from a user’s perspective with the Wonder Wheel and the use of filters for the type of result.
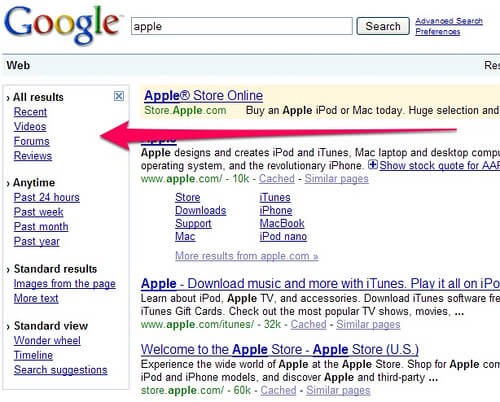
- Passive refinements of research, through signs based on previous researches or the analysis of the user behavior with similar intents and query (for example, RankBrain in 2017)
- Completion of the user experience for ambiguous query through SERP, enriched by carousels, users’ questions, and multiple knowledge graph panels to make clear all the possible meanings
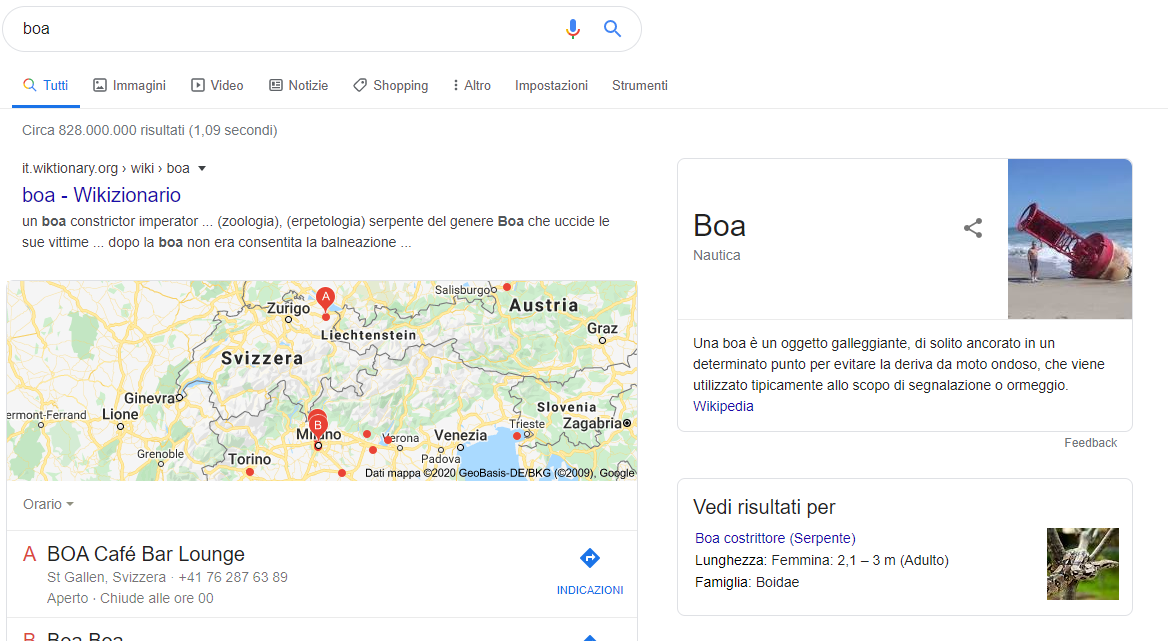
Google has always found the way, with more or less efficient methods, to improve their answers without disappointing the intent and expectations of the user. But what does the BERT add and why does Google call it revolutionary?
BERT Bidirectionality, or better, not directionality
The natural language models applied so far to train machines were implemented through the textual content vectorization (like the TF-IDF) or the frequency analysis and occurrences of the terms used, therefore, in a directional way, to the word analyzed to find the relationships between the entities: consequentially, the relationship was univocal and within the corpus of the text, the context between the entities was perceived partially.
With BERT, Google has implemented the coding part of the language with a Transformer (a mechanism aiming at finding relationships between words and parts of a word within a text) in a bidirectional way, or even better, without any direction, analyzing all the words within the text and linking all the entities available. The texts used for the BERT training came from Wikipedia allowing, therefore, the analysis of complete and exhaustive texts with defined relationships. The 15% of the texts have been covered through a process called MLM (Masked Language Modeling), allowing BERT to predict them based on the context (NSP: Next Sequence Prediction).
To achieve this, Google has created a computational hardware infrastructure to support the BERT training: BERT showed to be innovative also from this point of view, using the latest TPU Cloud.
As our mind works unconsciously, Google has been able to replicate with BERT the mechanism of comprehension, compared to other context-free algorithms like word2vec, which allows us to understand in a few phases if we are talking about a boa as a reptile or as an accessory for our masquerade party: the context.
What are the changes in Google with BERT
BERT will support RankBrain, without replacing it, as an integral part of the algorithm to comprehend the user queries: in fact, the second one lays as a support of the association between similar queries, synonyms, and misspelling.
What changes in SERP is a deeper understanding of the context of the user research, giving to the results a less literal interpretation. In the past, in regards to the query displayed as an example on the blog post by Google, which is “do estheticians stand a lot at work”, Google would have tried a matching approach for the query. Now, the match is at a contextual level providing, therefore, an answer more satisfying for the user:
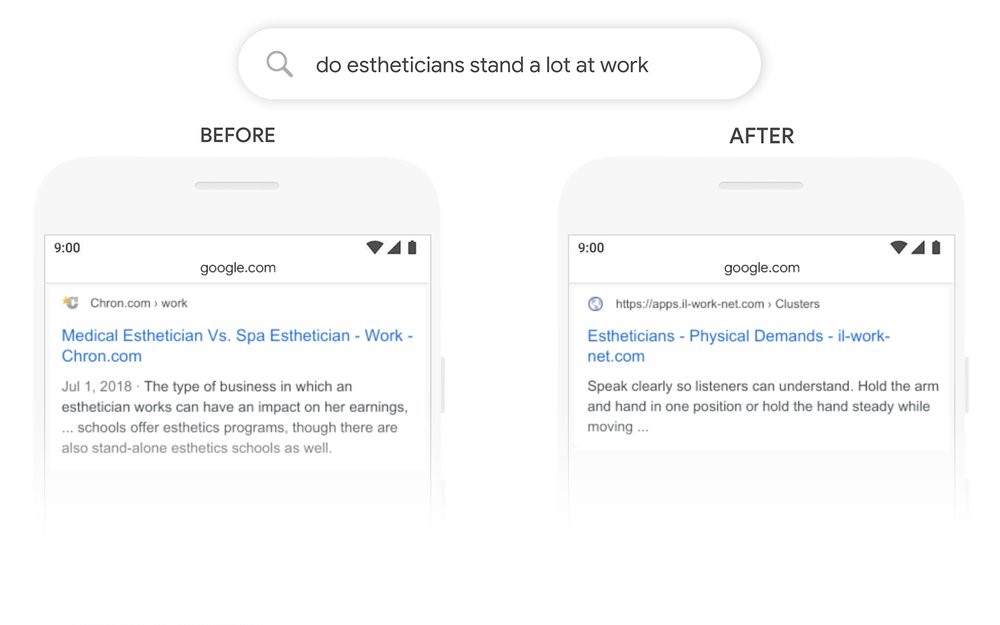
In a world in which many queries are conversational, Google needed to carry out this kind of approach, avoiding a user loss because of answers way too distant from the intent.
Afterward, Bing announced his BERT implementation to its algorithm, using Azure systems for the training: a sign that the satisfaction of the answers based on the context is a necessary condition for every search engine.
How BERT changes SEO
Ironically and eloquently, on the stage of the PubCon, Gary Ilyes has offered “A curriculum for optimizing for BERT”: it is not possible to optimize a text or a content to adapt to BERT if not answering to the user with your contents.
Unless you have been in a cryogenic suspension for the last 5 years, this should be the only SEO approach: identify your audience, analyze questions and concerns, and try to create a quality content that can justify the existence of the content itself, without forgetting the only thing we know about the algorithm, the SERPs and their characteristics, which tell us how Google interprets the intent.
The notes “SEO Friendly” or “SEO Copywriting” don’t exist anymore, and it is replaced by a user – centric writing in equilibrium with the scope of our site or our client’s one: writing to satisfy a need around a topic, without inflating our index with a thin or a humanly awful content due to stuffing queries and keywords.
